In almost every computer system there are resources that are shared among two or several tasks. That means that these resources need to be protected from having more than one task using them at the same time. This protection mechanism is called mutual exclusion. The most common mechanism used is semaphores. But there are many other ways to create mutual exclusion, all of them with different advantages and disadvantages.
Why do we need mutual exclusion mechanism?
Most systems have resources that are shared among several tasks (or processes). Normally a shared resource can only be used by one task at a time, and in some rare cases only by a limited number of tasks at the same time. Examples of shared resources could be:
- Data in buffers or structures in memory
- Non-reentrant code
- I/O device registers
- Devices like files, printers, modems etc
- Single data that cannot not be accessed by an atomic instruction
The section of code, which accesses a shared resource, is called a critical section of code. To be able to stop several tasks from accessing this critical section we need to protect it with a mechanism called mutual exclusion. This means that e g if one task is already accessing a critical section, and is preempted by another task that wants to access the same critical section, then the second task has to wait until the first task has finished accessing the critical section.
Things can easily go wrong
Let’s start with a very simple example to be able to see how easily things can go wrong if we forget to protect a shared resource. Figure 1 shows the design of a system that measures e g speed and outputs the actual speed value on a display.
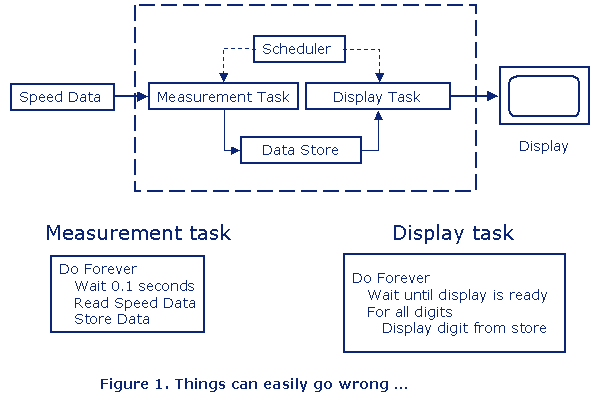
The Measurement task is periodic task with a period of 0.1 second and has the highest priority and it reads the input data and stores the data in shared data buffer. The Display task executes more like a background task, and the task reads the data from the data buffer and outputs the data on a display. The data buffer is the shared resource, and there is no protection from having one task writing data and another task reading data at the same time. And that means that things can go wrong, see Figure 2.

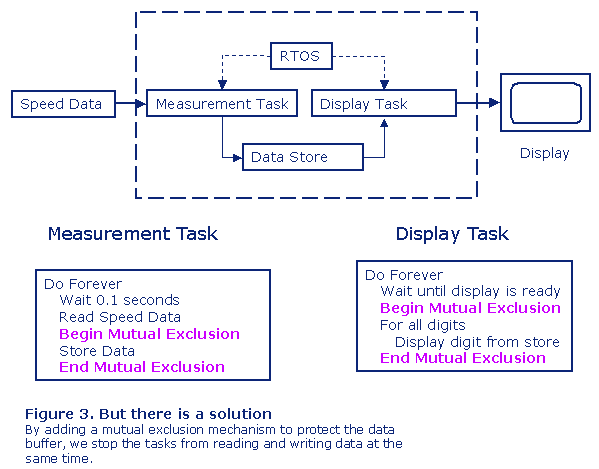
It may look harmless that for a fraction of a second a completely wrong value is displayed, but we can easily understand that a similar design in another application may be a very serious problem. To be able to correct the design we need to protect the data buffer using mutual exclusion as in Figure 3.
Different Mechanisms for Mutual Exclusion
So from the example above it is obvious that we need a mutual exclusion mechanism. There are several ways of creating such a mechanism. So which one should we use? The different mechanisms that will be handled in detail in this article are:
- Binary Semaphore
- Mutex Semaphore following
- Priority Inheritance Protocol
- Priority Ceiling Protocol
- Preemption Lock
- Interrupt Masking
- Message Queue
- Atomic Access
- Buffer with index whose access is atomic
Mutual exclusion with a binary semaphore
By using a binary semaphore only one shared resource can be protected. If you have several identical resources and you want to protect all of them by the same semaphore, then you need to use a counting semaphore. Figure 4 shows a typical example where both Task A (low priority) and Task B (medium priority) are using the same shared resource. A binary semaphore protects the resource.
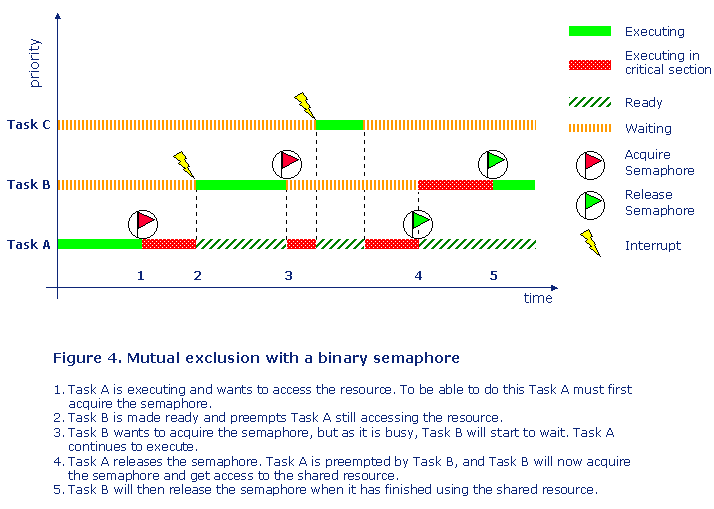
So in this typical example we see that a task with lower priority can delay the execution of another task with higher priority.
So solving the problem with protecting a shared resource, created another problem, a task stopping another task with higher priority from executing. If the priorities of the tasks using the same semaphore are close then this is normally not a problem. But if the difference is large, e g having a high-priority task and low-priority task sharing the same shared resource protected by a semaphore, then this can cause a serious problem known as priority inversion.
Priority inversion
In figure 5 we see almost the same situation as in the previous example, but in this case the semaphore is shared between the high-priority Task C and the low-priority Task A.
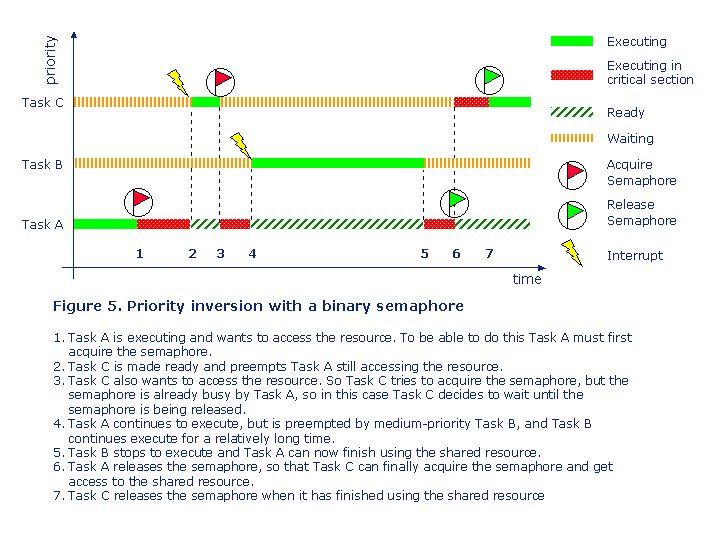
In this example the situation is much more critical, as Task C may have to wait not only for a semaphore used by low-priority task, but also for medium-priority tasks which are not involved at all in using the shared resource. So Task C may have to wait for a relatively long time, which may stop Task C from meeting its deadline, and a high-priority task normally has a short deadline. This problem is known as priority inversion. The best way to solve this problem is to identify all shared resources during the software design phase, and to see if any of those shared resources are shared between two or several tasks with a large difference in priorities. If possible then try to change the design so that this is not the case. If there is no better design solution, a mutual exclusive semaphore so called mutex may rescue you, but as we are going to see it may also add new problems.
Mutual Exclusion with a Mutex Semaphore
One of differences between a semaphore and a mutex is that a mutex has an ownership, which means that only the task that has acquired the mutex is the only task that can release it. This also means that a mutex cannot be used by an interrupt service routine, which is normally the case for a semaphore.
Priority Inheritance vs. Priority Ceiling
There are two well-known protocols for mutex semaphores, Priority Inheritance protocol and Priority Ceiling protocol. But it is also possible to have the mutex not using any of these two protocols, than the mutex works in the same way as a normal semaphore, and using the mutex this way is normally only done when the ownership is of essential use.
Priority Inheritance Protocol
When a task tries to acquire a mutex, which is already owned by another task with lower priority, then the priority of the task that owns the mutex is automatically raised to the same level as the priority of the other task.
Figure 6 shows the behavior of a mutex following the Priority Inheritance protocol.
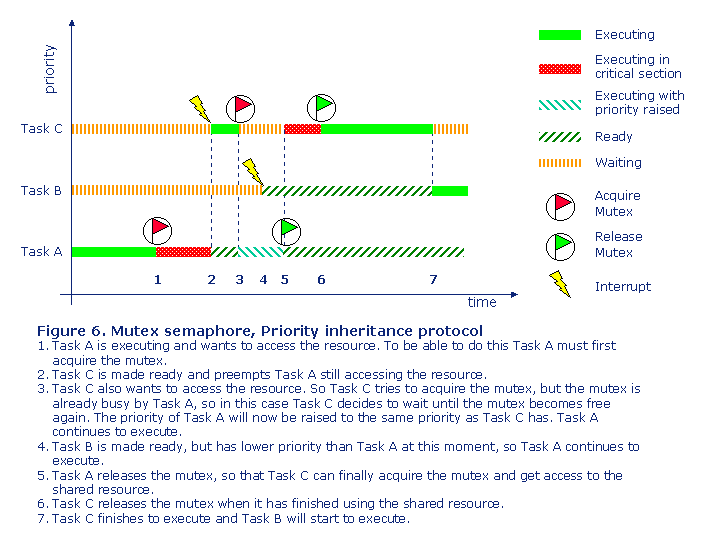
So by comparing this example with the one in figure 5, by using a mutex instead of a semaphore the high-priority task only needs to wait for the task owning the mutex. So medium-priority tasks will not delay the high-priority task. But as always there is price that someone has to pay, and in this case it is the medium-priority tasks, so you have to make sure that they also in this case meet their deadlines, as they are delayed as the protocol did raise the priority of the low-priority task.
Priority Ceiling protocol
When a task acquires the mutex then is the priority for that task immediately raised to what is called the ceiling priority, which normally is equal or a little bit higher than the highest priority of all tasks that can acquire the mutex, see Figure 7.
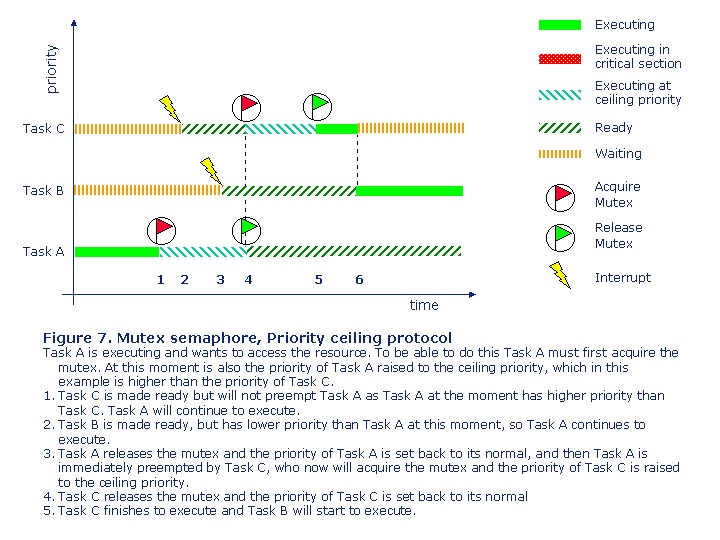
So again the high-priority task only has to wait for the low-priority task, and again the medium-priority tasks are delayed, so you have to make sure that they also meet their deadlines.
So which protocol is the best? As always it depends on the design of the application, but normally the priority ceiling protocol is better, as it will cause less context switches, meaning that the application will become a little bit faster. It also protects you against deadlocks if you have several mutex semaphores, and it also makes the timing analysis less complicated, but on the other hand you must be able to decide what should be the ceiling priority.
Limitations of mutex semaphores
So is using a mutex instead of a semaphore the perfect solution? If you do not have any deadlines, yes! But in real-time applications we always have deadlines, so why could there be problem using a mutex? To be able to verify that each task meets its deadline (which in many cases is a very hard thing to do), we want the task priorities to be static, meaning that they are not changed by the application, or at least we want to have full control when they are changed. But mutex semaphores using both Priority Inheritance protocol and Priority Ceiling protocol will automatically change priorities for those tasks using the mutex semaphores, and it is very hard to control when exactly this is happening, and this may cause a dynamic behavior of your application that could be impossible to test and to verify that each task meet its deadline every time.
Another limitation of a mutex is that it has no counting mechanism, even if the same mutex may be called recursively by the same task. If a counting mechanism is needed then you should either use a counting semaphore or a message queue.
Disabling preemption
A very simple but maybe a little bit drastic way of protecting a shared resource is to disable preemption. That means that you stop the scheduling of tasks, meaning that the executing task continues to execute till it either blocks or enables preemption. It is a very fast operation to change preemption mode, normally the RTOS just needs to set a flag, but it also means that all other tasks are stopped even those tasks that do not want to access the shared resource. See figure 8.
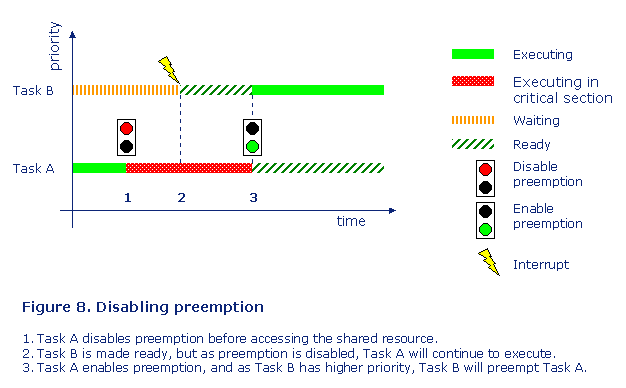
This mechanism should only be used for extremely short intervals, as otherwise there is a risk that a task with higher priority will fail to meet its deadline. Another limitation is that this mechanism only works when the shared resource is shared among tasks, as disabling preemption does not affect the interrupt services routines.
Interrupt masking
So if a shared resource is shared between a task and an interrupt service routine, then the task can disable interrupts before entering the shared resource. This will stop the ISR from accessing the shared resource, see figure 9.
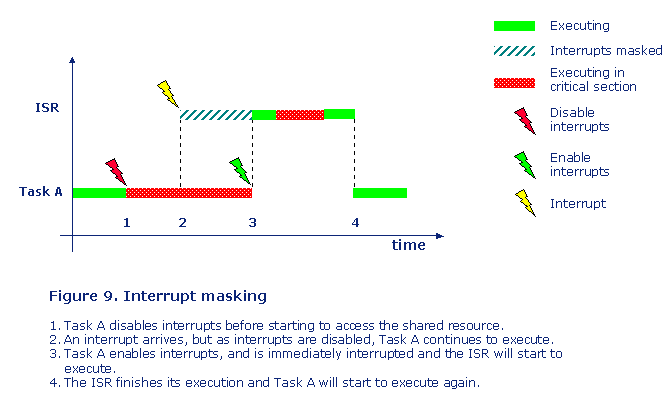
Again this is a very drastic mechanism, as it could mean that either all or at least lower-priority interrupts (depending on the CPU) are disabled at the same time, and those interrupts may not want to access the shared resource. This mechanism should also only be used for extremely short intervals, so that deadlines related to the other ISR:s are not missed. So this mechanism should normally only be used when both the task and the ISR needs to access the shared resource very frequently.
Mutual Exclusion using Queues
If the shared resource is data, many times the best solution is to use a message queue, meaning that one task sends the data in a message to message queue and another task reads the message from the message queue and in that way gets access to the data. A message queue both solves the problem with mutual exclusion and it also has built-in synchronization. But it is more time consuming than other mechanisms, as copying data takes time, but of course it is also possible to just send a pointer to a buffer to get a better performance.
Example of mutual exclusion without a RTOS call
If the shared resource can be accessed with an atomic CPU instruction like reading or writing single data or single I/O address, then there is no need for any mutual exclusion.
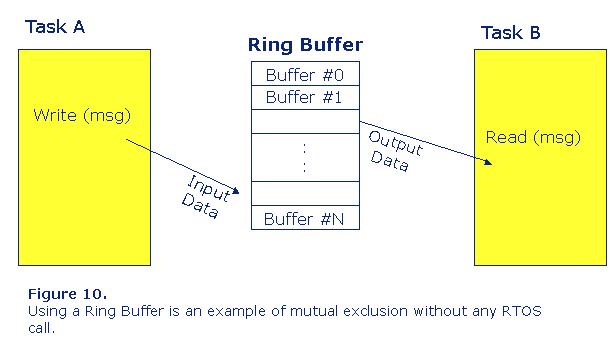
If using a message queue is too time consuming an alternative mechanism could be to use a ring buffer instead, see figure 10. But that means that the synchronization between the tasks using the shared resource has to be solved in another way using e g events or a semaphore. It is also necessary to know the maximum size of the data packets so that the ring buffer can be correctly dimensioned at design level.
Caveats of RTOS mutual exclusion mechanisms
Which ever mechanism that you decide to use it costs CPU time independently of the fact that they can cause a context switch, delay tasks or interrupts. It is also a very common cause for problems both during the design, implementation and test phase of your system. Just imagine that a task in a very special situation enables mutual exclusion for a shared resource and forgets or fails to disable it again. This may cause many sleepless nights for you.
So the absolutely best solution is of course to avoid shared resources, and that means that they need to be identified during the design phase, and then you need to find another and hopefully a better design, in which the resource is not shared any longer. And that normally means that it is just one and only one task that can access the resource.
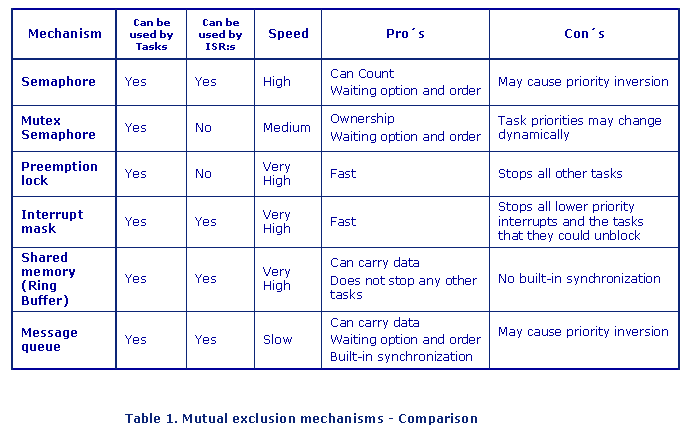
Mutual exclusion mechanisms comparison
If you cannot find a design in which you can avoid having shared resources, which mechanism should you use? As always it depends. Some questions that you may have to ask yourself may give some guideline.
- How time critical is this part of the code?
- Does it include sharing data?
- Is the resource shared only between tasks, or between tasks and ISR:s?
- Do I need to protect more than one identical resource with the same mechanism?
- Do I need synchronization at the same time?
- Is it OK to stop all other tasks?
- Is it OK to stop interrupts for a while?
So answering these question and doing a deep analyze should help you to select the best mechanism. And hopefully Table 1 will be helpful too.